UML diagrams are pure graphs. But EA uses a relational database (Microsoft Access for local repositories) behind the scene, so it has to press the graphs into a relational data model. This article shows some of the more strange results of this data structure mismatch.
- Many foreign keys and join tables
- Sparse tables with many NULL fields
- Multifunction fields
- Multifunction fields with foreign keys
- Inkonsistent data
Joining tables is quite expensive. And adding indexes will also add additional load onto the database, because every insert will cause the index to be recreated.
Graphs represent connected and semi-structured data. A class has different properties than a
In the central table t_object there are several columns PDATA1 to PDATA5, which store different information for different elements. For example, a UML part belongs to a class and EA stores the GUID of the class in PDATA1. So this cell is also a foreign key in case of UML part.
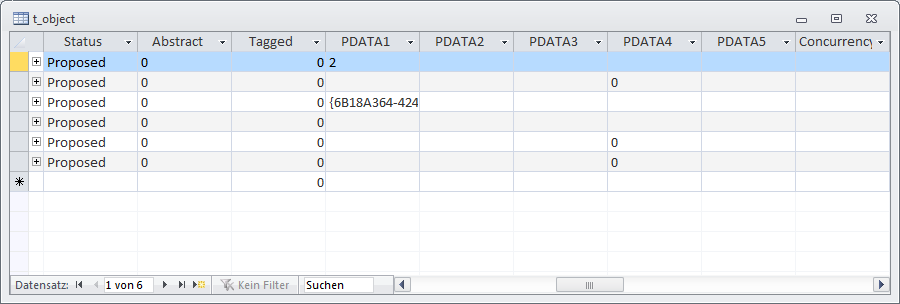
Another example is the handling of conveyed items. An Information Flow represents the flow of Information Items between elements. EA stores the references to this Information Items in table t_xref, which itself is some kind of multifunction table. The data is stored in column “description” (!) and can actually contain a list of foreign keys.
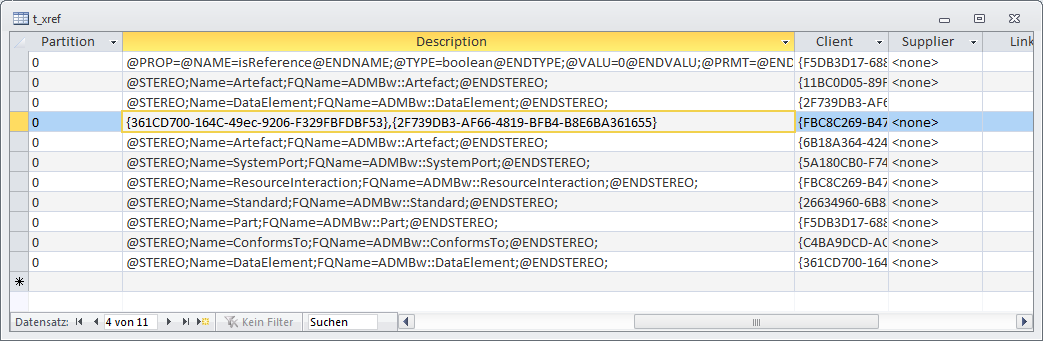
Handling all those special cases and foreign keys is a quite tough job for the app. Deleting an element in project browser
EA does not do this. So after a deletion, the database is in an inconsistent state.
Using Sparx Enterprise Architect as a modeling tool, this handling will not effect you. But it is a problem when you want to retrieve information from the repository.
The API just reflects this database structures.
- Retrieving data is slow
- Preparing the SQL for even simple analysis is catchy
- Programming analysis features is very cumbersome and time-consuming